Features
- Text-Guided Image Generation and Editing: Generate coherent images and edit them based on text prompts, seamlessly integrating textual instructions into the visual content.
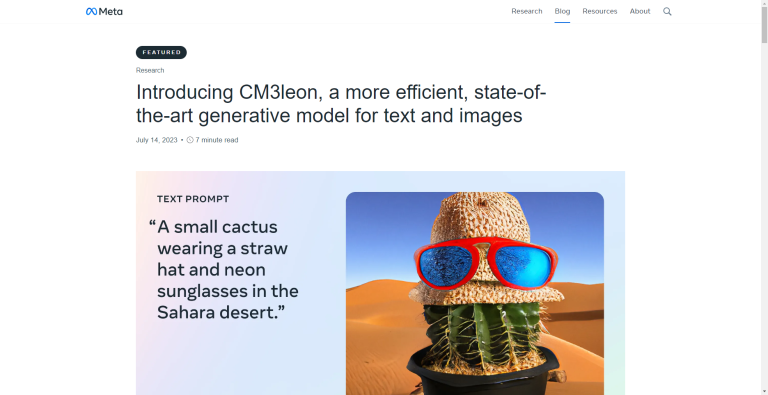
- Text-to-Image Generation: Create images that adhere to complex text prompts, incorporating compositional structure for rich and detailed visual output.
- Text-Guided Image Editing: Edit images by following text prompts, considering both textual instructions and the existing visual content for precise modifications.
- Text Tasks: Generate captions, answer questions about images, and describe images based on text prompts, showcasing versatile text-to-image capabilities.
- Structure-Guided Image Editing: Perform visually coherent edits to images while adhering to provided structural or layout information, ensuring a harmonious visual result.
- Object-to-Image: Generate images based on text descriptions of bounding box segmentation, providing flexibility in content creation.
- Segmentation-to-Image: Produce images based on image segmentation without text classes, offering diverse possibilities in visual generation.
- Super-Resolution Results: Enhance image resolution through separately trained super-resolution stages, delivering higher-quality visual output.
Use Cases:
- Image Generation and Editing: CM3leon excels in generating and editing complex images based on text prompts and instructions, providing a versatile tool for creative endeavors.
- Text-to-Image Generation: CM3leon is adept at producing coherent images aligned with intricate text prompts, showcasing its prowess in text-to-image generation.
- Visual Question Answering and Captioning: CM3leon shines in answering questions about images and generating captions based on text prompts, facilitating seamless vision-language tasks.
CM3leon stands as a state-of-the-art generative model, seamlessly combining text-to-image and image-to-text generation capabilities. It delivers impressive performance across diverse vision-language tasks while maintaining optimal efficiency.